From Historical Sources to Datasets: A Preview of DataScribe
Updated November 11: The beta release is now available for download (zip file).
Scholars in history and related humanities fields are increasingly turning towards data analysis and visualization in order to understand the past. Historians have of course long used sources with quantitative informations, such as probate records, tax lists, bills of mortality, censuses, and the like. The mass digitization of historical records has only made those types of sources more readily accessible.
And yet there is a huge gap between having a historical source (even a digitized one) and having a dataset which can be analyzed. By analogy, you can think of the difference between having an image of a manuscript and having a text transcription of that document. But with datasets, the problem of transcription is even more difficult, because data has structure. For example, historical documents may have many small variations in how they are laid out, but when transcribed they should all use the same variable. Or it may be important to standardize the transcription of a set of categories. Historians and scholars who are creating their own datasets have been transcribing them in software not really designed for the purpose, perhaps in spreadsheets. But those ad hoc approaches have many limitations. (Believe us, we’ve run into them many times!) And those limitations great affect the speed, accuracy, and usability of the datasets that are transcribed.
Enter DataScribe. In September 2019, the NEH’s Office of Digital Humanities awarded RRCHNM a grant to develop software to tackle just this problem. We have been diligently—but quietly—developing this software over the past year. As we approach our initial round of testing outside of RRCHNM, we are ready to start giving you previews of what this software will be able to do.
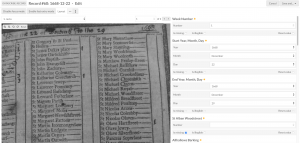
DataScribe is built on the Omeka S platform. Many, many humanities projects are already using Omeka S to describe and display collections of historical sources. You will be able to add the open-source DataScribe module to Omeka and use it to transcribe historical sources. You can define what a dataset should look like: the variables you are going to transcribe and the types of data (numeric, categorical, textual, as well as custom data types) that go into those variables. Teams of people will then be able to transcribe the sources, and we are building in a workflow for reviewing and managing transcriptions. Transcribers will see the historical sources side by side with the fields they need to transcribe, and managers will be able to see the status of the project. While this software is in very rapid development and will continue to change, you can get a sneak preview of what it looks like in the screenshots at the end of this post.
So, when can you get your hands on DataScribe? The answer is soon. DataScribe is currently alpha software, and you can follow its development and open issues at our GitHub repository. On November 11 we will move into our first round of public beta testing. If you are interested in testing DataScribe—or even just want to receive periodic updates about the project—please fill out this very brief form. We will add you to a mailing list to keep you up to date about the project, and if you indicate an interest in testing we will be back in touch with the details. Our project website and the draft documentation are also great ways to learn about the project.
One of the ways that humanities discipline is moving forward is by creating (and sharing) new datasets. Very few historians working with data are dealing with off-the-shelf datasets which are already ready to be analyzed or visualized. To create new historical or humanities knowledge, scholars need to be able to create new datasets. And that is what DataScribe will help them do.
Screenshots of the DataScribe module (click for full resolution images)

DataScribe allows users to see the documents they are transcribing, to enter the transcription into fields that ensure data accuracy and consistency, and to manage the workflow of the project.

DataScribe also allows transcribers to focus just on the document and the fields that they need to enter.

Project managers can use DataScribe’s form builder to define which fields should be transcribed and to decide which types of data, such as numbers, dates, and categories, should be associated with those fields.